Control and automation are fundamental to modern systems, allowing machines and processes to operate with minimal human intervention while maintaining precision and efficiency. At the heart of these systems lies feedback, a mechanism that continuously monitors the system’s output and compares it to a desired target or setpoint. If a difference is detected — known as an error — the controller automatically adjusts its output or behavior to correct it. Feedback loops can be simple, like a thermostat turning heating on and off to maintain room temperature, or highly complex, such as in industrial robots that adjust their movements in real-time based on sensor data. By using feedback, automation systems become dynamic and self-correcting, capable of adapting to disturbances, uncertainties, or changing conditions without constant manual oversight. This principle makes feedback essential for ensuring stability, accuracy, and resilience across everything from household appliances to large-scale manufacturing plants.
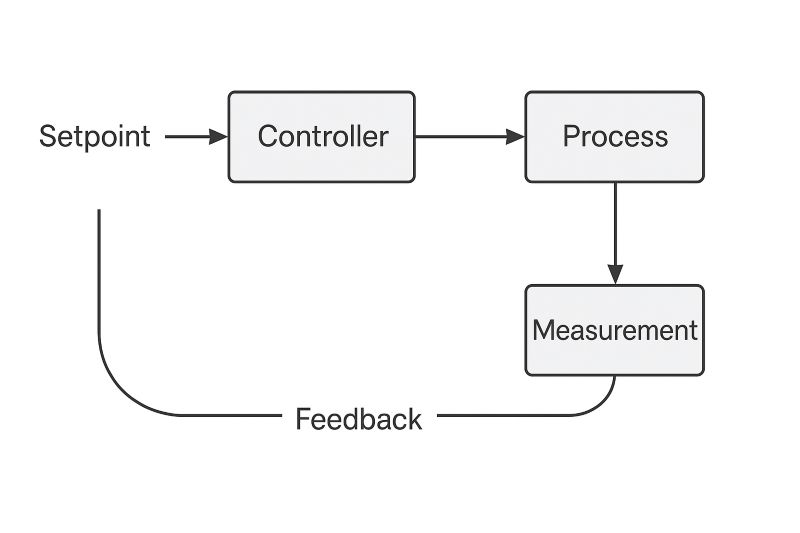
Modern digital control feedback loops use sensors, digital processors, and actuators to automatically manage systems in real time. Sensors measure the system’s output, convert it into digital signals, and send it to a controller (like a microcontroller or PLC). The controller compares the measurement to a desired setpoint, calculates any error, and computes a corrective action using algorithms like PID control. This output is then sent to actuators to adjust the system.
Example: A digital thermostat reads the room temperature every second, compares it to the setpoint, and adjusts the heater’s power automatically to keep the room comfortable.
Supervisory setpoint control is a control strategy where a higher-level system (the supervisor) oversees and adjusts the setpoints of lower-level controllers in real time, based on broader goals or changing conditions.
Here's how it works:
- Each local controller (like a thermostat) focuses on maintaining a simple, fast task — like keeping temperature at a setpoint or keeping speed constant.
- The supervisory controller sits above them and doesn't control the process directly. Instead, it dynamically updates the setpoints given to these local controllers based on bigger-picture information — like system-wide optimization, environmental changes, or future predictions.
For example, in a smart building: Local thermostats control the temperature in each room. A supervisory system monitors weather forecasts, energy prices, and occupancy patterns, and adjusts the setpoints for the thermostats to save energy while keeping comfort. In short:
- Local controllers = follow setpoints fast and reliably.
- Supervisor = decides what the setpoints should be based on higher-level thinking.
Is generative AI ready to compute setpoints for supervisory automation? Can it be relied upon to provide correct and accurate data without having to be specially trained to solve the problem at hand? The answer is, maybe yes.
Scenario: In a smart energy management system for a large office building, an AI model is tasked with optimizing indoor climate control for both comfort and energy efficiency. Every five minutes, the AI receives a prompt containing updated sensor data: current indoor temperatures, weather forecasts, occupancy levels, and real-time electricity prices. Based on this information, the AI computes the optimal indoor temperature setpoint that balances comfort with minimizing energy costs. It then sends this setpoint to the building’s HVAC controller. The HVAC system uses the new setpoint to adjust heating and cooling outputs, dynamically responding to both external conditions and operational goals. This supervisory control loop runs continuously, allowing the building to maintain ideal conditions while adapting automatically to changing environments and market signals.
The AI model in the above scenario needs to be capable of logic and computation. Which of the many models available can accurately and consistently provide the best and most accurate answers using zero-shot learning? In AI and machine learning, zero-shot learning means a model can correctly handle tasks or recognize things it was never specifically trained on. It relies on general knowledge or understanding, not memorization.
AI models differ in capability based on factors such as the amount and quality of training data, the complexity of their architecture, and the size of the model in terms of parameters. Larger models, like GPT-4, typically have more advanced reasoning, language understanding, and problem-solving abilities because they can capture more intricate patterns and relationships. However, smaller models may be faster, cheaper, and better suited for specific tasks where deep complexity is unnecessary. The training objective also shapes a model’s capabilities — some are optimized for general conversation, others for specialized tasks like medical analysis or code generation. Fine-tuning and alignment further refine models, allowing them to behave safely and effectively in particular domains. Additionally, some modern models are multi-modal, meaning they can process not just text but also images, audio, or video, significantly expanding what they can do. Ultimately, a model’s strength depends not just on size, but on how well its design, training, and purpose fit the intended application.
How about letting multiple AI's compete with each other to determine a winner? This approach is widely used in trusted fault-resilient systems so why not use it for AI inference?
Trusted, fault-resilient systems using multiple redundancies are designed to maintain correct, secure, and reliable operation even when parts of the system fail or are compromised. These architectures employ redundancy by running multiple independent subsystems or components in parallel, often with diversity in hardware, software, or design to reduce the chance of common-mode failures. When a fault occurs, trusted mechanisms like voting algorithms, failover switching, or reconfiguration logic detect the issue and isolate or replace the faulty component without interrupting the overall service.
Examples of fault-resilient trusted systems using multiple redundancies include:
- Spacecraft with triple-redundant flight computers, voting logic, and secure communication links to Earth.
- Financial trading platforms that operate across multiple mirrored servers, ensuring transactions are both completed and secure even during hardware failures.
- Military defense networks that route commands and intelligence across redundant, encrypted channels so that attacks or node failures cannot compromise overall mission control.
Trusted Fault-Resilient AI Data Agents
Multiple independent AIs compute in parallel, a broker compares and votes on results, ensuring only the most trusted and resilient output reaches the application.
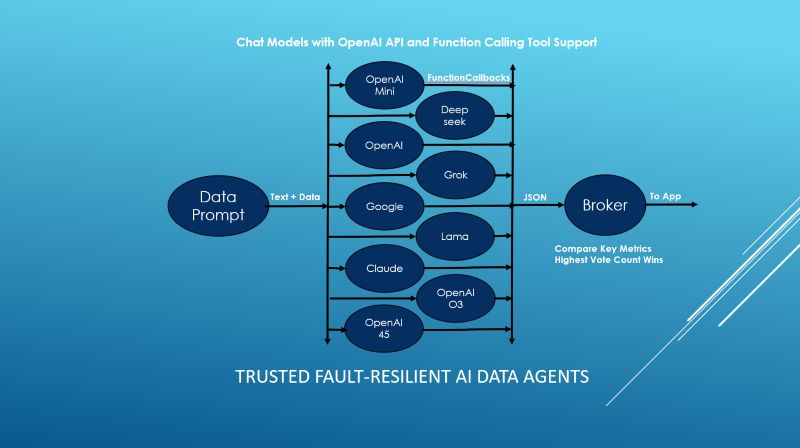
The architecture presented in "Trusted Fault-Resilient AI Data Agents" outlines a distributed AI processing system engineered for both fault resilience and trust assurance. The system input is a Data Prompt that encapsulates structured input, a combination of text instructions and accompanying data payload. This prompt is broadcast in parallel to a heterogeneous ensemble of AI models, including instances like OpenAI Mini, Deepseek, OpenAI (4o), Grok, Google, Lama, Claude, OpenAI O3, and OpenAI 45.
Each AI model independently computes its inference response, formatted in standardized JSON, ensuring downstream compatibility. All models utilize function-calling tool support when forwarding their response to the Broker.
The Broker operates as a trusted arbiter, executing a multi-value comparative analysis across the model outputs. It extracts key-value responses from the JSON message before applying a voting-based consensus mechanism. The winning output, determined by the highest scoring or most consistently supported result, is forwarded onto the application.
Voting starts when the first result is received by the Broker. When the voting interval (e.g., 30 sec.) ends, the Broker compares each model result with all the other models and receives a vote for every match. The first AI that reaches the minimum vote threshold is the winner. This threshold is based on the number of AI models and the confidence level desired. One match is low confidence up to eight which is a perfect score with very high confidence. I found that four matches works well and gives the system high resilience. Your mileage may vary.
This fault-resilient framework ensures that multiple points of failure: degraded outputs, model unavailability, or anomalous behavior will have minimal impact on the output. Moreover, the diversity across models enhances fault independence, mitigating risks from correlated common-mode failures (e.g., shared training biases or infrastructure outages). In essence, this system fuses redundancy, diversity, and dynamic validation into a scalable trusted AI inference fabric.
Trusted Fault-Resilient AI Data Agents – Flow Overview:
- Data Prompt Generation
- Gather input text + structured data to form a unified prompt.
- Broadcast to Multiple AI Models using OpenAI Chat API
- Send prompt in parallel to models: (OpenAI Mini, Deepseek, OpenAI, Grok, Google, Lama, Claude, OpenAI O3, OpenAI 45)
- Independent AI Inference
- Each model processes the prompt independently.
- Model outputs utilize function-calling tools which send messages in standardized JSON format
- Collection of Responses
- Gather all model JSON responses into a data buffer.
- Broker Aggregation and Evaluation
- Broker compares relevant JSON key-value responses
- Voting system applied: highest agreement or score wins.
- Result Forwarding to Application Layer
- The validated, trusted result is sent to the application for real-world use.
Screenshot of Dueling AIs:

Python sample code is available on GitHub: https://github.com/upperbayhawk/C2_AIAgentsPublic
Having fun with AI! Dave Hardin